
人类一直没有停止过探索世界的脚步,从古至今,我们一直渴望着能够找到一种方法能够预测未来,解决人类生存最原始的焦虑,从伏羲八卦到现代自然科学,无不在通过对自然界的观察和各种数据中提取规则,希望能够应对各种不确定性。在这过程中出现了数学、统计学、概率论、信息论、模式识别等等学科,用来解释自然的规律,在历史长河中也闪耀着巨匠的名字:香农,费雪,图灵……。机器学习和深度学习也是其中的一种方法,那究竟什么是深度学习?它是怎样构成的?它能够解决一些什么样的问题?如何通过程序去编写一个深度学习的程序并将它应用在实际的问题解决中?开个博文来记录自己的学习过程,所有记录过程都来自于我对机器学习和深度学习的一些疑问,欢迎各位大佬指点讨论。
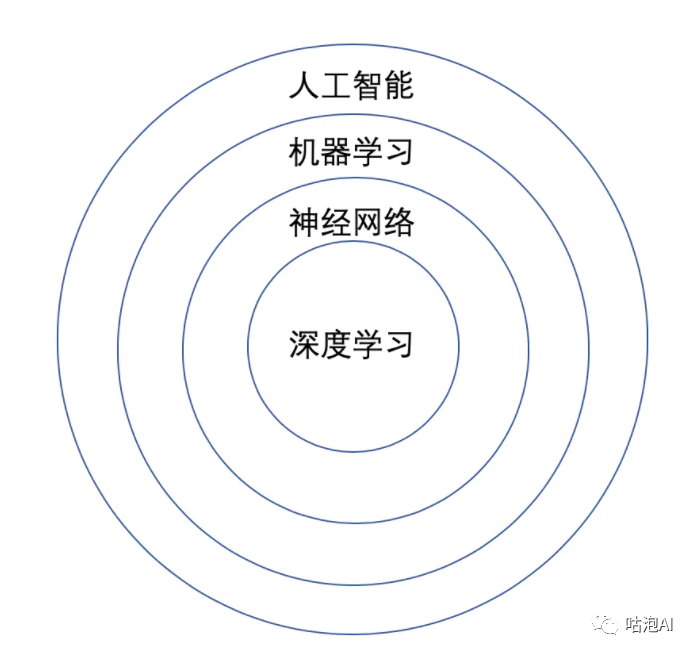
在讲深度学习之前,我们现在听过了太多的名词,人工智能,机器学习,神经网络,深度学习,那么他们之前是一种什么样的关系呢?画了一张图来表示一下,深度学习是神经网络的分支,神经网络是机器学习的一种方法,机器学习是人工智能的一种分支,知道这个之后至少不会被一堆名词搞晕了。
既然深度学习是机器学习的一种,那先了解下在计算机这么发达的今天,我们为什么需要机器学习?随着计算机科学的发展,现在有大量的程序猿在编写代码,通过逻辑和数据结构为我们构建一个一个的程序,来帮助我们的生活,但是在编程的过程中,有一些问题很难通过常规的规则和逻辑编程来实现,比如从图片中识别这是不是一只猫,这个对于人来说很简单的事情,对于计算机来说却难于上青天。
若假设所有图像的高和宽都是同样的 400 像素大小,一个像素由红绿蓝三个值构成,那么一张图像就由近 50 万个数值表示。那么哪些数值隐藏着我们必要的信息呢?是所有数值的平均数,还是四个角的数值,抑或是图像中的某一个特别的点?事实上,要想解读图像中的内容,你需要寻找仅仅在结合成千上万的数值时才会出现的特征,比如边缘、质地、形状、眼睛、鼻子等,最终才能判断图像中是否含有猫。
一种解决以上问题的思路是逆向思考。与其设计一个解决问题的程序,我们不如从最终的需求入手来寻找一个解决方案。事实上,这也是目前的机器学习和深度学习应用共同的核心思想:我们可以称其为“用数据编程”。与其枯坐在房间里思考怎么设计一个识别猫的程序,不如利用人类肉眼在图像中识别猫的能力。
我们可以收集一些已知包含猫与不包含猫的真实图像,然后我们的目标就转化成如何从这些图像入手来得到一个可以推断出图像中是否含有猫的函数。这个函数的形式通常通过我们的知识来对针对特定问题选定:例如我们使用一个二次函数来判断图像中是否含有猫。但是像二次函数系数值这样的函数参数的具体值则是通过数据来确定。
通俗来说,机器学习是一门讨论各式各样适用于不同问题的函数形式,以及如何使用数据来有效地获取函数参数具体值的学科。深度学习是指机器学习中的一类函数,它们的形式通常为多层神经网络。
那什么是神经网络呢?
最早的神经网络Perceptron(感知机)诞生于1960年代,被誉为迈向类人机器智能的第一步。1969年,麻省理工学院的马文·明斯基(Marvin Minsky)和西摩·帕尔特(Seymour Papert)发表了著作《Perceptrons》,用数学的方法证明这种网络只能实现最基本的功能。这种网络只有两层神经元,一个输入层和一个输出层。辛顿在1986年取得了突破,他发现反向传播可以用来训练深度神经网络,即多于两层或三层的神经网络。但自那以后又过了26年,不断增强的计算能力才使这一理论得以证实。辛顿和他在多伦多的学生于2012年发表的一篇论文表明,用反向传播训练的深度神经网络在图像识别领域打败了当时最先进的系统——“深度学习”终于面世,并在过去十多年内推动着图像识别、语音识别、机器翻译、广告点击预测等各领域的快速发展。
从直观上来看看神经网络长什么样呢?
首先来看神经元,通过树突接收各种电信号,然后通过细胞核处理,然后由轴突传递给到相关联的其他神经元。
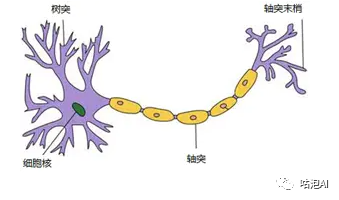
但是对于计算机来说要怎么去表达呢?我们先看一个最简单的神经元:
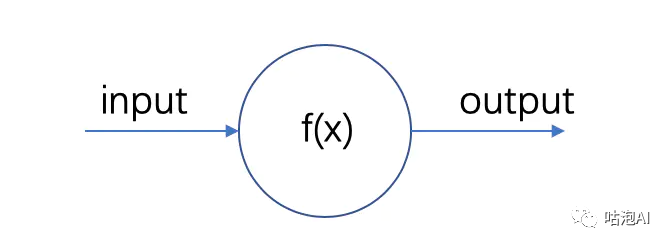
将这个模型再通用化一点,接收多个输入,然后通过激活函数,将数据的数据映射为一个输出:
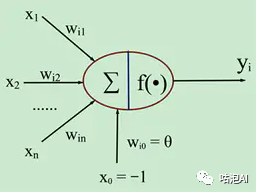
然后看神经网络,神经网络就是在神经元的基础上像对积木一样,将神经元连接起来,这样就形成了一个神经网络,那深度学习就是在神经网络的基础上,增加更多的隐藏层,能够拟合更复杂的问题。
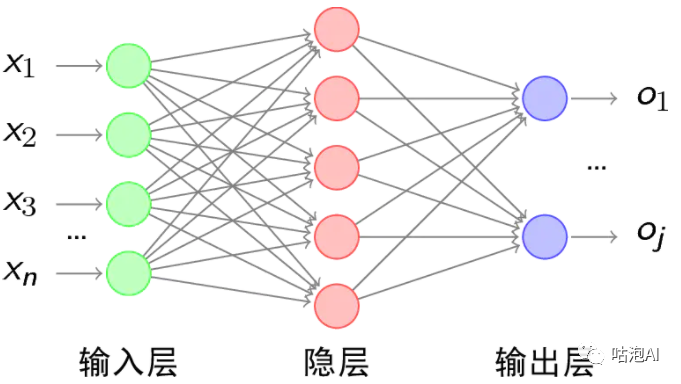
那神经网络是不是万能的呢?
神经网络或者深度学习在广告预测、图像识别、语音识别等等领域广泛应用,从目前来看,神经网络创造价值基本是基于监督学习的,什么是监督学习?简单来多就是我们知道训练样本的输出y。在实际的使用当中,机器学习解决的大部分问题都是监督学习问题。我们来看看机器学习在现实中的一些应用,然后看看在不同应用场景下的神经网络有什么不同。

在吴恩达的深度学习课程中,给出了上面的一些例子,用来说明神经网络的一些应用场景和需要的不同的神经网络模型,对于一般的监督学习问题,我们使用标准神经网络就行了,而对于图像识别问题,我们则常用CNN,对于像语音识别这样处理序列信号时,我们则需要考虑使用RNN,还有更多更复杂的应用则需要多种模型进行混合使用。这里又出现了一些新名词:CNN,RNN,那什么时CNN?什么是RNN?先从直观上来看看长什么样子,具体的学习则留在后面进行。
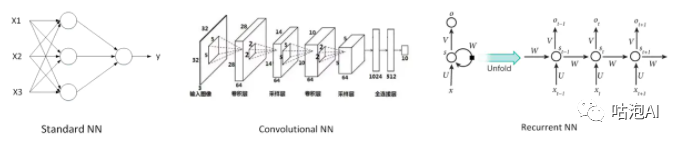
前面在了解深度学习的历史时提到,辛顿在86年就提出了利用反向传播算法来训练深度神经网络,为什么在时隔26年后才风靡开来,为什么深度学习能够在各个领域带来如此大的提升?吴恩达教授给了一张很形象的图来解释这个问题:
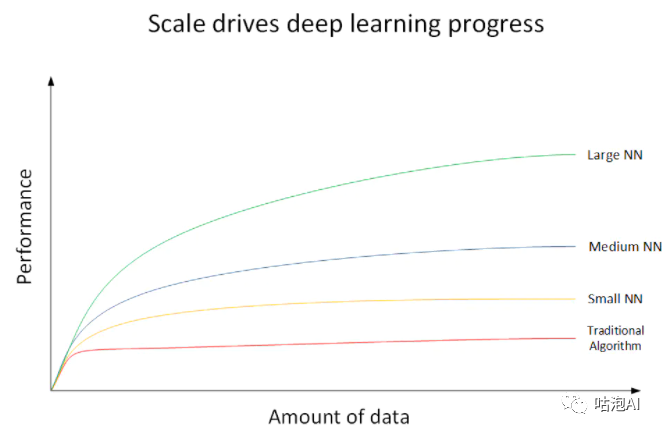
从这张图上可以看到,在小数据量的时候传统的机器学习算法的表现是比较好的,但是随着数据量的逐步增加,大规模的深度神经网络的表现会远远优于其他算法,而且基本保持了上升的趋势,而近些年来,随着数字化的进程加快,传感器设备的飞速增长,我们对数据的采集变得越来越容易,每天在互联网上会产生海量的数据,数据量呈几何增长,加上GPU的出现,算力大幅提升,使得深度学习能够在更多方面有更好地表现。当然还有算法的不断提升,例如:神经网络神经元的激活函数是Sigmoid函数,后来改成了ReLU函数、优秀的容量控制方法,例如丢弃法、记忆网络和神经编码器—解释器这样的多阶设计使得针对推理过程的迭代建模方法变得可能等等,当然还有各类深度学习的框架:如TensorFlow,Caffe 2,PyTorch,CNTK,MXNet等,大大推动了深度学习的发展和广泛的应用。简要来说:数据、算力、算法、产业投入共同造就了深度学习的繁荣。
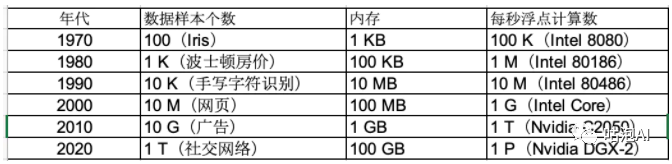
未来已来,随着物联网时代的到来,从人人连接,人物连接到万物连接,传感器数量爆发增长,区块链技术带来更加安全的数据交易和共享,数据量将还会有大的提升。算力方面:GPU、量子计算机等,会带来算力的大幅提升。从产业和研究上看,深度学习依然是热点,大量的学校企业投入进行研究,相信深度学习在未来还会能够有更好地表现,当然也希望能够出现更好地模型和算法,替代掉深度学习,推动着整个社会智能化的车轮不断滚滚向前。
来源:咕泡AI